Life Sciences
Taking the Measure of Cancer, Genomically
Besides collecting and freely sharing cancer genome data, research organizations and consortia are integrating genomic and clinical information and offering…
To understand what you must do to deal with or defeat an enemy, you must take their measure. That is, you must assess their character and abilities. And if you come to know your enemy deeply and comprehensively, so much the better. That is the principle behind cancer genomics or, more specifically, the amassing of cancer genomics databases.
Although cancer genomics relies on huge data stores, the discipline is agile and full of urgency, which is fitting because cancer, a leading cause of death, is affecting more people year by year. According to the International Agency for Research on Cancer, new cancer cases numbered 19.3 million across the globe in 2020, and they are expected to reach 30.2 million by 2030. Over this period, deaths attributed to cancer will also increase, from 9.96 million to an estimated 16.3 million.
To ensure that the tide of battle against cancer is turned sooner rather than later, large organizations and consortia have been building—and enhancing—publicly available cancer genomics databases. Just because these databases are publicly available doesn’t mean they are readily used. That is, the genomic information that the databases provide may not be clinically actionable unless it is complemented by clinical information. Also, raw information may need to be accompanied by analysis.
Such enhancements are the focus of this article. They are helping large organizations build cancer genomic databases that are more than static monuments. These databases are all about being nimble. They typically provide multiple access options, visualization tools, and analytical packages. Ultimately, their purpose is to match patients with the most effective treatments.
Building on a rich legacy
The landmark cancer genomics program known as The Cancer Genome Atlas (TCGA) has molecularly characterized over 20,000 primary cancers and matched normal samples spanning 33 cancer types. “No one has done genomics at the scale the National Cancer Institute (NCI) and the National Human Genome Research Institute (NHGRI) achieved through TCGA,” says Jean Claude Zenklusen, PhD, deputy director at the Center for Cancer Genomics.

Although TCGA contains clinical data, improvements are desirable. “We do not have good information about treatment regimens and outcomes,” Zenklusen admits. “Those data are important to understand which mutations sensitize patients to specific therapies. We now characterize clinical trial samples that have very good clinical parameter annotations in the Center for Cancer Genomics’ current programs.”
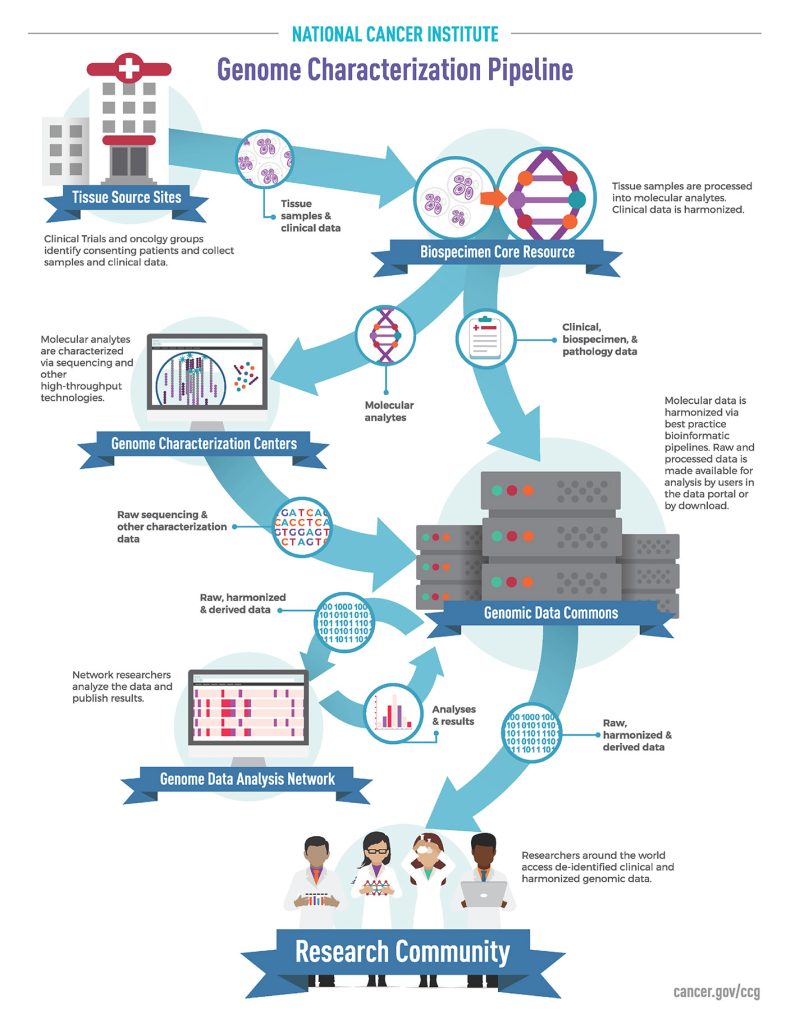
A major part of the Center for Cancer Genomics’ current work is in making the data available and accessible to all researchers, accomplished largely by building a data portal with multiple data access options and analysis and visualization tools.
The original portal, the Cancer Genomics Hub, only allowed downloading, restricting the types of users and usability of the data. A next-generation cancer knowledge base, the Genomic Data Commons, not only holds data for download but also contains a suite of analytical tools. The Genomic Data Commons incorporates approximately 5 petabytes of data and close to 1 M files from both the NCI and outside groups.
“We have data from the Multiple Myeloma Research Foundation, the Clinical Proteomic Tumor Analysis Consortium, the Molecular Analysis for Therapy Choice clinical trials, and other sources,” Zenklusen remarks. “For some projects, the clinical data are considerable. Foundation Medicine contributed data on 18,000 patients. An Italian research group contributed 150 lung tumor genomes from asymptomatic patients that were identified through a northern Italian CT scan project that evaluated 40,000 heavy smokers.”
With the vast amount of data in the Genomic Data Commons, connecting researchers with the data and helping them make use of it is key. “We needed a portal that allowed people to explore the data,” Zenklusen notes. “Ninety percent of the data is accessible without credentials.”
Besides making data publicly available, the Genomic Data Commons works with the Genomic Data Analysis Network, a group of experts that provides analysis and coordinates with external disease experts to address relevant questions. When an analysis is completed, a description of the results is published, and the analyzed data are made publicly available on the Genomic Data Commons publication page.
“Projects with actionable results are taken up quickly by oncologists,” Zenklusen emphasizes. “We will be able to make a change in patient treatment, but we need larger populations and more clinical data. The goal is to transform cancer from an acute lethal disease into a chronic manageable one.”
International efforts
The International Cancer Genome Consortium (ICGC) was established to sequence 25,000 cancer genomes. As part of the effort to reach this goal, the ICGC incorporated TCGA data. Subsequently, the ICGC launched a second initiative: the Pan-Cancer Analysis of Whole Genomes (PCAWG), an international collaboration to identify common patterns of mutation in whole genomes.
To build on these initiatives, Andrew V. Biankin, AO, the ICGC’s executive director and the Regius Chair of Surgery at the University of Glasgow, launched Accelerating Research in Genomic Oncology (ARGO). ARGO has three goals: 1) Determine how to use current treatments better by assembling the clinical data to decipher response and resistance. 2) Improve our understanding of lethal versus nonlethal cancers. 3) Begin implementing precision oncology in healthcare.
“We need to transition from understanding the genome’s structure to clinical utility,” Biankin declares. “We need to move to creating data parcels that will inform treatment decisions robustly and also be feasible for healthcare systems to implement.” To facilitate this transition, the ICGC is launching a Lancet Oncology Commission, a global team with expertise across healthcare systems that intends to develop a strategic framework for leveraging genomic knowledge.
“Our goal is to deliver 1 million patient years of precision oncology knowledge—200,000 patients with 5 years of follow-up,” Biankin stresses. The ICGC-ARGO platform is open. The ICGC’s genomes plus additional submissions have been reanalyzed and realigned with the latest version of the human genome using upgraded analysis pipelines. To date, data are promised from 75,000 committed donors.
Clinical data are the biggest challenge due to the legal and policy framework that has evolved with the General Data Protection Regulation, which European Union countries interpret differently. “A modified version of this regulation for health data for research would greatly facilitate data gathering,” Biankin suggests. “Instead of learning from 1–2%, we want to analyze and profile every patient’s sequences.”
Understanding data provenance is important. “[It helps to] communicate with the data generators because there may be nuances around a data parcel,” Biankin explains. “For example, one pancreatic cancer data parcel might relate to early-stage resected disease, and another to metastatic disease.”
The ICGC encourages data sharing and has implemented a structure that initially limits access to the data generators, and that gradually opens up in a controlled, tiered fashion.
Bias in databases
Underrepresentation of individuals of non-European ancestry in genomic databases has research and clinical ramifications. “We use public databases such as TCGA and the 1,000 Genomes Project as references, and their underrepresentation of minority groups biases results,” says Yan W. Asmann, PhD, associate professor of biomedical informatics, Mayo Clinic. “Clinical practice is equally affected.”
For instance, tumor mutational burden is an FDA-approved biomarker of patient selection for certain cancer immunotherapy drugs. The most accurate tumor mutational burden estimate requires patient-paired tumor and germline (peripheral blood) sequencing to filter out non-somatic mutations. However, since blood samples are not routinely collected in clinics for germline analysis, tumor mutational burden is often calculated from tumor-only sequencing relying on public germline variant databases to filter out non-somatic variants, leading to inflated tumor mutational burden estimates in underrepresented minorities and, consequently, to patient selection errors.
Asmann adds that the collection of genomic sequencing data from patients of non-European ancestry is insufficient not only in terms of quantity, but in terms of quality. While studying seven selected cancer types from TCGA, Asmann and colleagues found that tumor DNA from African American patients was sequenced less deeply. “This was not intentional or by design,” Asmann suggests. “It was due to timing. TCGA studied African American patients later than patients of European ancestry, and in general, samples studied earlier were sequenced more deeply.”
However, even when sequencing depths are comparable, African American samples have more genomic positions with insufficient coverage, possibly due to the bias in DNA capture kit design, which is based on the racially biased reference genome. Most of the genomic data that was used to create the reference genome came from individuals with European ancestry. Consequently, capture probes designed based on the reference genome are more specific for ancestral European genomes and capture less well for others.
To address this disparity, race-specific reference genomes are beginning to be compiled by the scientific community. “The Mayo Clinic is very interested in establishing a position-specific ancestry map of the current reference genome and plans to perform genomic sequencing of every cancer patient,” Asmann points out. “African and Caucasian genomes differ by only about 1%, but some of the 1% positions are located in clinically important genes. We need to tailor the sequencing depths based on position and ancestry to ensure equal data qualities of ancestry-specific positions.”
Analytic tools for PCAWG
The ICGC/TCGA PCAWG project performed whole genome sequencing and integrative analysis on over 2,800 primary cancers and their matching normal tissues across 38 distinct tumor types. According to a preprint posted by the project’s Portals and Visualization Working Group, several publicly available online data exploration and visualization tools are available to view and analyze the data. Indeed, the preprint named five of these tools: the ICGC Data Portal, UCSC Xena, Expression Atlas, PCAWG-Scout, and Chromothripsis Explorer.
The ICGC Data Portal, a genome informatics program at the Ontario Institute of Cancer Research, is the main data dissemination platform for the ICGC. The portal can also be used to explore PCAWG consensus simple somatic mutations, including point mutations and small indels, each by their frequencies, patterns of co-occurrence, mutual exclusivity, and functional associations.
One of the preprint’s authors, Mary Goldman, design and outreach engineer, UC Santa Cruz (UCSC) Genomics Institute, is a good source of information about UCSC Xena. “It has many visualizations and analyses, including differential gene expression analyses, Kaplan Meier analyses, and more,” she says. “In particular, our Visual Spreadsheet, which integrates many different types of data, allows you to explore the rich datasets generated by the PCAWG Project.”
UCSC Xena also facilitates the exploration of data from sources such as the TCGA PanCancer Atlas, the Genomic Data Commons, as well as the UCSC Toil RNAseq Recompute Compendium with data from TCGA, the Therapeutically Applicable Research to Generate Effective Treatments program, and the Genotype-Tissue Expression project. It can also be used to securely view data from studies not hosted on UCSC Xena.
The Gene Expression team at the European Molecular Biology Laboratory’s European Bioinformatics Institute (EBI) developed and maintains the Expression Atlas, an open science resource that freely distributes information on the abundance and localization of RNA and proteins across species and biological conditions such as different tissues, cell types, developmental stages, and diseases.
In addition to the PCAWG datasets, the Expression Atlas has selected expression studies from archives such as ArrayExpress, Gene Expression Omnibus, and European Nucleotide Archive for further curation and processing. At present, the Expression Atlas provides results on over 3,500 experiments that include about 120,000 assays from over 60 different organisms.
The Genome Informatics Unit at the Barcelona Supercomputing Center developed and maintains PCAWG-Scout. PCAWG-Scout allows users to run their own analyses, including prediction of cancer-driver genes, differential gene expression, recurrent structural variations, survival, pathway enrichment, mutations as visualized on a protein structure, mutational signatures, and possible recommended therapies. The PCAWG portal holds only PCAWG data; other datasets have their own bespoke portals using the same technology.
Results of the PCAWG consortium revealed that cancer genomes often harbor highly complex genomic rearrangements, such as those caused by chromothripsis, which is a mutational process characterized by the massive accumulation of tens to hundreds of clustered structural variants. Chromothripsis Explorer provides functionalities to visualize genome-wide mutational patterns across the entire genome for all PCAWG tumors, with a focus on somatic structural variants and copy number aberrations.
Exploring TGCA
OncoDB is an online database developed at the University of Illinois Chicago, in a laboratory led by Xiaowei Wang, PhD, professor of pharmacology and bioengineering. The database facilitates the exploration of abnormal patterns in gene expression, particularly with respect to oncoviral infection. Specifically, OncoDB integrates TCGA RNA-seq, DNA methylation, and related clinical data in addition to the Genotype-Tissue Expression project as the normal tissues reference control.

“Unlike most laboratories, we have a bioinformatics capacity,” Wang asserts. “Initially, we built a tool for our own research. Then we expanded it for use by the entire community.” Although oncoviruses are a key component, OncoDB focuses on all cancer cases regardless of viral association. The format of the processed raw data allows keyword searches. Researchers can type in the gene code and receive relevant information like the expression profiles across different cancers and the associations with different clinical parameters. Such information can reveal how gene functions during cancer development and progression.
The Wang laboratory maintains and hosts OncoDB along with other online databases. “Our first database, miRDB for miRNA target prediction, was introduced 15 years ago,” Wang recalls. “It has been cited over 16,000 times. With OncoDB, our goal was not just to publish a paper but to make the resource useful to the community for the long term.”
A variety of graphs presents the results and provides access to publication-quality figures. “Our goal is to make the bioinformatics analysis easy for those who do not have our skills,” Wang explains. “Summarizing results can be an automated process. Information is also presented in table format for custom figures and graphs.”
“OncoDB took several years to develop,” Wang states. “Now, other researchers do not have to go through the same laborious process. Bioinformatics resources are surprisingly helpful in research, and we will continue to expand OncoDB and include more data types from TCGA and beyond. Our goal is to become the bridge between bioinformatics and bench scientists. The more OncoDB is used, the more impactful our work.”
The post Taking the Measure of Cancer, Genomically appeared first on GEN – Genetic Engineering and Biotechnology News.
bioinformatics
proteomics
genomics
immunotherapy
healthcare
regulation
fda
research
clinical trials












Wittiest stocks:: Avalo Therapeutics Inc (NASDAQ:AVTX 0.00%), Nokia Corp ADR (NYSE:NOK 0.90%)
There are two main reasons why moving averages are useful in forex trading: moving averages help traders define trend recognize changes in trend. Now well…

Spellbinding stocks: LumiraDx Limited (NASDAQ:LMDX 4.62%), Transocean Ltd (NYSE:RIG -2.67%)
There are two main reasons why moving averages are useful in forex trading: moving averages help traders define trend recognize changes in trend. Now well…

Asian Fund for Cancer Research announces Degron Therapeutics as the 2023 BRACE Award Venture Competition Winner
The Asian Fund for Cancer Research (AFCR) is pleased to announce that Degron Therapeutics was selected as the winner of the 2023 BRACE Award Venture Competition….
